In the realm of machine learning, the journey from raw data to effective models is paved with critical steps, one of the most vital being data preprocessing. This transformative process serves as the backbone of machine learning, enabling algorithms to learn from curated datasets rather than chaotic raw data. Data preprocessing revolves around cleaning, transforming, and preparing data to ensure that it aligns with the stringent requirements of machine learning models, which significantly impacts overall performance and accuracy.
Why is data preprocessing so crucial? The importance of this step cannot be overstated, as it lays the groundwork for successful applications of machine learning across various sectors, from finance to healthcare. Here are some key reasons:
- Enhances Quality: Data that is cleaned and well-organized leads to more reliable insights and sound decision-making, reducing the likelihood of errors that can arise from unprocessed information. For instance, a financial institution using precise data preprocessing can gain accurate risk assessments, which is vital for avoiding potential financial pitfalls.
- Improves Model Performance: Well-processed data can significantly boost the predictive power of algorithms. In practical scenarios, businesses that use preprocessed data often find that their customer segmentation models yield improved targeted marketing strategies, ultimately enhancing customer engagement.
- Reduces Complexity: A streamlined dataset makes it easier to understand, visualize, and interpret trends. This is particularly beneficial for data scientists who need to communicate findings effectively to stakeholders or non-technical team members.
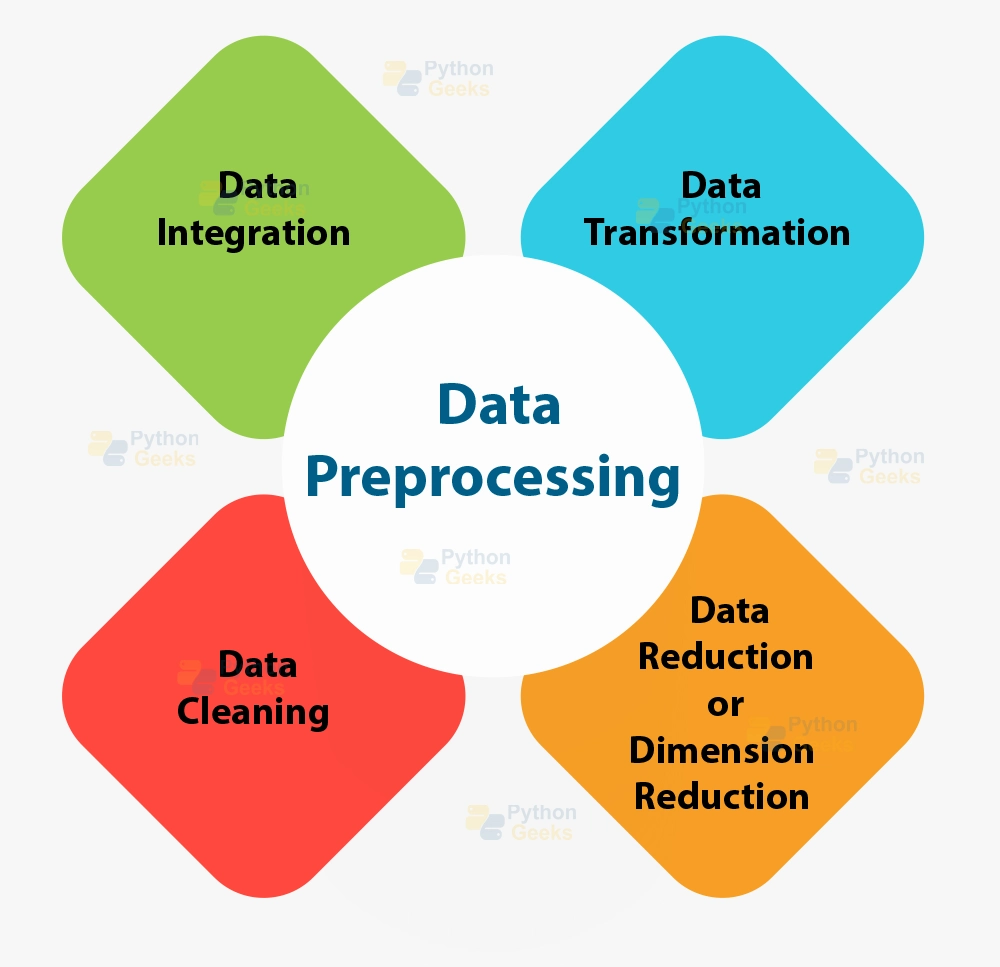
Common Data Preprocessing Techniques
Several techniques are commonly employed in data preprocessing, each serving a unique purpose in refining data:
- Data Cleaning: This involves identifying and rectifying inconsistencies and inaccuracies in the dataset. For example, missing values can be addressed either through imputation techniques or by removing incomplete records, thus ensuring that analyses are based on complete information.
- Normalization: This critical process scales numerical values to bring them into a similar range, which is essential for algorithms that rely on distance calculations, such as k-nearest neighbors. For instance, feature scaling can prevent attributes with larger ranges from overshadowing those with smaller ranges, leading to more balanced model training.
- Encoding Categorical Variables: Text data often needs to be converted into a numerical format for algorithms to process it effectively. Techniques like one-hot encoding or label encoding transform categories into numerical representations, enabling models to interpret non-numerical data seamlessly.
As the reliance on machine learning grows across industries in the United States, understanding these preprocessing techniques is essential. Organizations, whether in tech, healthcare, or retail, recognize that the effectiveness of their machine learning models often hinges on this foundational step. With rapidly evolving data landscapes, being equipped with the skills to preprocess data effectively allows businesses to harness the full potential of their datasets. In the following sections, we will delve deeper into each of these techniques and explore their profound impact on achieving successful outcomes in machine learning projects.
DISCOVER MORE: Click here for additional insights
Understanding the Essentials of Data Preprocessing
Data preprocessing is more than merely a technical necessity; it is a critical determinant of the effectiveness of machine learning models. Without adequate preprocessing, models can become burdened with noise and irrelevant information, leading to inaccurate predictions and subpar performance. The importance of investing time and resources in data preprocessing is evident across various industries in the United States, where decision-makers are increasingly reliant on data-driven insights.
One of the primary tactics in data preprocessing is data cleaning, which ensures datasets are free from errors that could mislead the training process. Common issues include duplicate entries, incorrect data entries, and the pervasive problem of missing values. These issues can silently distort the outcomes of machine learning models if not addressed. For example, in the healthcare sector, inaccurate patient records can hinder effective treatment plans, while in finance, faulty entries can lead to investment strategies that carry excessive risk.
Another cornerstone technique is normalization. By scaling features to a common range, normalization makes it easier for algorithms like neural networks or support vector machines to converge quickly during training. This is particularly important in models sensitive to the magnitude of input features. For instance, in a real estate prediction model, the size of properties (in square feet) and their prices can vary widely; without normalization, price predictions may fluctuate wildly, resulting in unreliable expert analyses.
The Importance of Encoding Categorical Variables
Encoding categorical variables is yet another vital preprocessing step, particularly when dealing with textual data. Machine learning algorithms inherently function with numerical data, necessitating the transformation of categorical variables into a numerical format. Techniques like one-hot encoding or label encoding provide effective solutions for this challenge, allowing algorithms to parse complex information efficiently. In practice, consider a retail business using customer data to improve marketing strategies. By encoding demographics like gender or location, the model can discern patterns and preferences that inform targeted marketing efforts.
These preprocessing techniques, while sometimes overlooked, are instrumental in shaping the success of machine learning models. Organizations must not only understand these methods but also recognize their transformative potential when applied properly. As we continue to explore the major preprocessing techniques, it becomes clear that they are not just technical tasks but strategic elements that significantly enhance model accuracy and efficacy.
In a rapidly evolving data landscape, companies in the tech, healthcare, and retail sectors must prioritize data preprocessing as foundational in their machine learning initiatives. A strong preprocessing strategy can yield highly impactful results, supporting businesses to exploit insights effectively and navigate towards success in data-driven environments.
The Importance of Data Preprocessing Techniques
Data preprocessing is an indispensable step in the machine learning workflow. It encompasses a variety of techniques aimed at transforming raw data into a format that is more suitable for analysis. Such techniques can significantly impact the performance of machine learning models. First and foremost, data cleaning is crucial. Any data inconsistencies, missing values, and outliers need to be addressed to ensure the integrity of the dataset. Applying methods like mean or median imputation for missing values or using robust statistics helps to enhance model accuracy. The process of standardization or normalization of features is also vital, allowing algorithms that rely on distance measurements, such as k-nearest neighbors, to work effectively without being affected by scale differences in the data.Moreover, feature selection and extraction can further enhance model performance. By identifying and keeping only the relevant features, models can avoid the issues of overfitting and reduce computational costs. Techniques such as Principal Component Analysis (PCA) help to distill the most critical data while eliminating noise.Lastly, data transformation, through techniques like encoding categorical variables or discretization of continuous variables, prepares the data adequately for various algorithms, ensuring compatibility. Exploring these preprocessing methods not only lays a solid foundation for constructing robust machine learning models but also helps in achieving higher accuracy and generalizability across different datasets.
| Preprocessing Technique | Importance |
|---|---|
| Data Cleaning | Removes inaccuracies and ensures quality, thereby enhancing data reliability. |
| Feature Selection | Reduces overfitting while improving model performance on unseen data. |
The above points underscore how vital the role of data preprocessing is in maximizing the effectiveness and efficiency of machine learning models, ultimately leading to better outcomes in predictive analytics and decision-making processes.
DISCOVER MORE: Click here for further insights
Enhancing Model Performance through Feature Engineering
Beyond data cleaning and encoding, feature engineering stands as a cornerstone of effective data preprocessing in machine learning. This process involves creating new input variables or modifying existing ones to better capture the underlying patterns within the dataset. By extracting meaningful information, feature engineering can significantly enhance the predictive capabilities of machine learning models.
A powerful illustration of feature engineering can be found in the financial sector, where analysts often create complex features from raw data. For example, a bank might generate a feature from a customer’s transaction history that aggregates total spending or calculates the average transaction frequency. Such features can directly influence credit scoring models by providing more context about a customer’s financial behavior. This additional insight allows the model to make more informed predictions regarding loan approvals or risk assessments, underscoring the importance of meticulous feature engineering.
Data Transformation Techniques
Another vital aspect of preprocessing involves data transformation, which adjusts the distribution of features to improve model performance. Techniques such as log transformation, square root transformation, or Box-Cox transformation can normalize skewed distributions, leading to more stable and reliable predictions. For instance, in the real estate market, property prices often exhibit a skewed distribution due to a handful of extremely high-value properties. Applying a log transformation can smooth out this skew, enabling algorithms like linear regression to perform better by adhering to the assumptions of normality.
In addition, the presence of outliers in a dataset can severely distort model training. Techniques such as winsorization or z-score analysis help identify and mitigate the impact of outliers. For example, in predictive maintenance for manufacturing equipment, a sudden equipment failure can lead to an unusually high value in the dataset. By addressing these outliers through preprocessing, machine learning models can become more robust, yielding predictions that are not overly influenced by anomalous data points.
Splitting the Data: Training, Validation, and Testing
Equally crucial is the proper splitting of data into training, validation, and testing sets. This ensures the model is not only trained on one portion of the data but is also validated and tested on unseen data. This approach minimizes the risk of overfitting, where the model learns noise and random fluctuations instead of the underlying trends. In practice, a standard approach is to allocate approximately 70% of the data for training, 15% for validation, and 15% for testing. These allocations empower data scientists to fine-tune hyperparameters on validation data and assess the model’s generalizability through testing.
As organizations scramble to harness the power of machine learning in various fields—ranging from healthcare to marketing—the emphasis on robust preprocessing cannot be overstated. Businesses that overlook critical data preprocessing steps risk jeopardizing their analytical goals. By investing in comprehensive data preprocessing strategies—spanning data cleaning, encoding, feature engineering, transformation, and proper data splitting—decision-makers can unlock the full potential of machine learning models, paving the way for insightful, actionable outcomes in a competitive marketplace.
DISCOVER MORE: Click here for more insights
Conclusion
In the ever-evolving landscape of machine learning, the significance of data preprocessing emerges as a critical factor that can make or break model effectiveness. As organizations increasingly leverage data for decision-making, understanding that the quality of input data directly influences outputs is paramount. The journey from raw data to actionable insights requires meticulous attention to aspects such as data cleaning, feature engineering, and data transformation techniques.
Comprehensive preprocessing not only aids in crafting a more robust dataset but also enhances model performance by ensuring that algorithms are trained on relevant, high-quality features, rather than being skewed by outliers or irrelevant information. Furthermore, the significance of appropriately splitting data into training, validation, and testing sets cannot be underestimated. This practice ensures optimal performance while reducing the risk of overfitting, thus helping models generalize better to real-world scenarios.
Ultimately, organizations that prioritize effective data preprocessing will not only improve their predictive modeling efforts but also gain a strategic edge in the competitive landscape. Investing time and resources into preprocessing strategies is a proven approach to unlocking the full potential of machine learning models, transforming raw information into valuable insights that drive informed decision-making. As we continue to advance in this data-driven era, the art of preprocessing will remain a vital cornerstone in the efficacy of machine learning applications across industries.
Related posts:
The Impact of Data Preprocessing on the Accuracy of Artificial Intelligence Models
Ethical Challenges in Data Processing for Artificial Intelligence Projects
The Intersection of Data Processing and Artificial Intelligence in the Financial Industry
The Importance of Data Quality in Processing for Machine Learning Algorithms
The Impact of Real-Time Processing on Decision Making in AI
The Role of Real-Time Data Analysis in Enhancing Artificial Intelligence Systems
Beatriz Johnson is a seasoned AI strategist and writer with a passion for simplifying the complexities of artificial intelligence and machine learning. With over a decade of experience in the tech industry, she specializes in topics like generative AI, automation tools, and emerging AI trends. Through her work on our website, Beatriz empowers readers to make informed decisions about adopting AI technologies and stay ahead in the rapidly evolving digital landscape.